")
《Hello AI》Jetson Nano构建Jetson-inference(Build from source)
Jetson Nano构建Jetson-inference的方法有:
Build from source 从源码构建
Docker
本教程为了方便说明,会把jetson-inference安装在用户目录中,通常是/home/username,例如本文用户目录就是/home/shawn
在命令行输入以下命令,在当前目录跳转到用户目录:
cd运行以下命令,更新并安装一些依赖项:
sudo apt-get update
sudo apt-get install git cmake libpython3-dev python3-numpy运行以下命令,把Jetson-inference项目克隆到本地:
git clone --recursive --depth=1 https://github.com/dusty-nv/jetson-inference
git clone命令用于克隆远程仓库。这个命令中的参数含义如下:
--recursive:表示在克隆仓库的同时,也递归地克隆仓库中的所有子模块。
--depth=1:表示只克隆最近的一次提交记录,不包括仓库的完整历史纪录。这可以加速克隆过程。
克隆完成后,运行ls命令,可以看到当前目录下多了一个名为「jetson-inference」文件夹

进入jetson-inference的目录:
cd jetson-inference创建build目录,并且进入build目录:
mkdir build
cd build使用CMake,搜索上一级目录中的源代码,进行配置和生成Makefile文件:
cmake ../个命令中的
cmake是CMake软件的执行命令,它用于配置和生成Makefile文件来控制软件的编译和构建过程。这个命令中的
../表示CMake搜索源代码的路径,它指向当前路径的上一级目录。
等待cmake完成的过程,
cmake期间,会提示是否安装PyTorch,
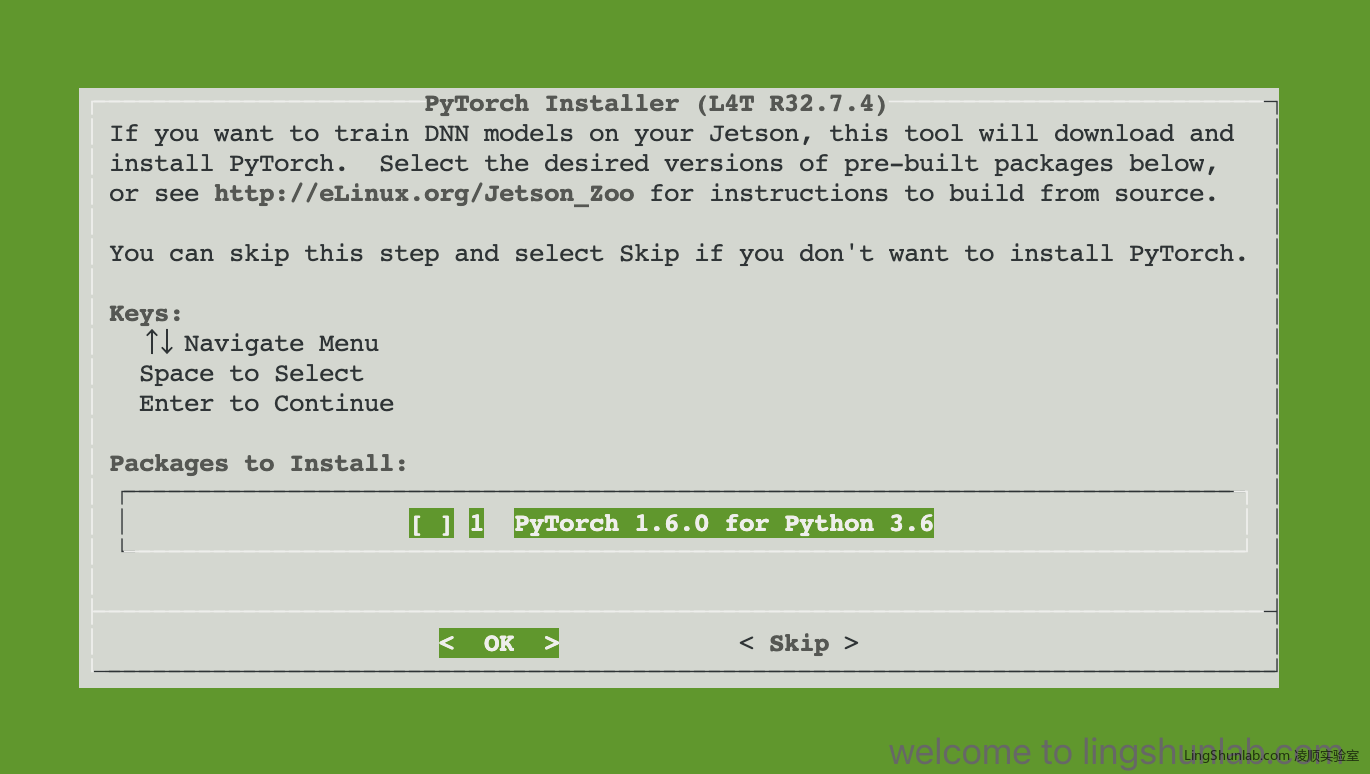
一般我都会选择安装的,在OK上按回车确认。
如果选择暂时跳过,要在其他时间安装 PyTorch的话,可以再次运行这些命令,进行PyTorch的安装:
cd jetson-inference/build ./install-pytorch.sh
cmake 完成之后,继续输入以下命令:
make -j$(nproc)
sudo make install
sudo ldconfig
make -j$(nproc)
- make命令用于根据Makefile文件编译源代码
-j$(nproc)参数表示开启多个进程并行编译,可以加快编译速度- $(nproc)会展开为CPU的核心数,以充分利用CPU资源
所以这条命令表示:使用make并开启CPU所有核心并行编译
sudo make install
- sudo表示以root权限执行命令
- make install表示根据Makefile安装编译生成的文件到系统目录
所以这条命令表示:用root权限执行make install,将编译好的文件安装到系统目录
sudo ldconfig
- ldconfig命令用于更新和配置动态链接库
- sudo表示以root权限执行
所以这条命令表示:用root权限执行ldconfig,更新动态链接库的配置
总结一下:
这三条命令常在编译安装软件时同时使用,用于高效编译、正确安装软件文件,并更新库文件配置。
经过一段时间的等待,终于构建完成了jetson-inference这个项目在本地了。
该项目将构建到jetson-inference/build/aarch64,具有以下目录结构:
|-build
\aarch64
\bin 样本二进制文件构建到的地方
\networks 网络模型存储的地方
\images 测试图像存储的地方
\include 头文件所在位置
\lib 库构建到的位置在构建树中,可以在build/aarch64/bin/中找到二进制文件,头文件在build/aarch64/include/中,库在build/aarch64/lib/中。这些也在sudo make install步骤中安装到/usr/local/下。
jetson.inference 和 jetson.utils 模块的Python绑定也在sudo make install步骤期间安装到/usr/lib/python*/dist-packages/下。如果更新代码,请记住再次运行它。
测试验证jetson-inference是否构建成功
我们运行一个简单的ImageNet对图像进行识别的例子程序,即可验证是否安装成功。
打开「jetson-inference」目录里的「build/aarch64/bin」
cd jetson-inference/build/aarch64/bin使用C++或Python变体通过程序对示例图像进行分类:
# C++
$ ./imagenet images/orange_0.jpg images/test/output_0.jpg # (default network is googlenet)
# Python
$ ./imagenet.py images/orange_0.jpg images/test/output_0.jpg # (default network is googlenet)注意:第一次运行每个模型时,TensorRT 将花费几分钟来优化网络。之后,此优化的网络文件会缓存到磁盘中,使得再次使用该模型的识别时间将变得更快。
在对应的目录中,生成了一张识别后的图片

恭喜你,已经完成jetson-inference在本地的构建安装。


