Anthropic 的宪法分类器,给“越狱”黑客们上了堂难度课
目录
來源是 Anthropic 頻道上傳的影片《Defending against AI jailbreaks》的文字稿总结
哈喽,各位对 AI 又爱又怕(或者单纯好奇)的朋友们!今天咱们来聊个硬核又有趣的话题:AI 安全。
现在的大语言模型,比如 Anthropic 家的 Claude,是越来越聪明了,能写诗、能写代码、还能陪你聊天解闷。但能力越大,潜在的风险也就越大。就像我们凌顺实验室 (lingshunlab.com) 一直关注的那样,总有人想“带坏”AI,让它说点不该说的、做点不该做的,这就是所谓的“越狱”(Jailbreaking)。是不是有点头大?别急,Anthropic 捣鼓出了一个挺有意思的解决方案,叫做“宪法分类器”(Constitutional Classifier)。今天,咱们就来扒一扒这玩意儿到底是怎么回事,它又是如何让 AI 变得更安全、更可靠,同时又不至于“傻”到啥有用的也干不了的。
AI“越狱”:不只是技术宅的“游戏”,为啥我们得操心?
“越狱”这个词,大家可能首先想到的是 iPhone 越狱,为了装点官方不让装的 App。AI 越狱差不多一个意思:想办法绕过开发者设置的安全防护栏,让 AI 模型输出一些开发者本意想阻止的有害内容,比如违法信息、歧视言论,甚至是协助进行危险活动。
你可能会说,现在 AI 好像也没那么神通广大吧?确实,目前阶段可能还好。但研究人员们(包括 Anthropic 这些大厂)担心的,是未来那些能力更强的模型。想象一下,如果一个 AI 能轻易帮你策划大规模网络攻击,或者提供制造危险物品的关键信息……那画面太美我不敢看。
尤其是所谓的“通用越狱”(Universal Jailbreaking),这玩意儿更让人头疼。啥意思呢?就是找到一种“万能钥匙”式的提示或方法,不管你想问什么歪门邪道的问题,用这个方法一套,AI 就乖乖“就范”了。想想以前,可能随便网上搜个“咒语”(特定的提示词),就能让 AI“放飞自我”,现在嘛...黑客们可能得加点班了。 通用越狱大大降低了作恶门槛,让没啥专业知识的普通人也能利用 AI 干坏事,这才是大家真正需要警惕的。
Anthropic 的“定海神针”:宪法分类器闪亮登场
面对越来越狡猾的越狱企图,Anthropic 觉得光靠模型本身的训练还不够。于是,他们基于自家的“责任扩展策略”(RSP,你可以理解为一套 AI 安全开发的行为准则),搞出了“宪法分类器”。
这名字听起来特正式,听起来有点‘高大上’,叫‘宪法’?其实就是一套用大白话写的规则,告诉 AI 什么能聊,什么碰都别碰。简单粗暴但有效! 这套“宪法”是用自然语言写的,比如明确规定“不能提供制造大规模杀伤性武器的信息”,同时也列出哪些是安全、无害的交流范畴,比如写诗、写普通代码。
然后,基于这套“宪法”,Anthropic 训练出专门的“分类器”模型。这些分类器就像是 AI 世界里的“安检员”和“巡逻警察”。
“瑞士奶酪”防御体系:层层设防,让 AI 安全滴水不漏
光有一个“安检员”还不够,Anthropic 玩的是“瑞士奶酪”模型(Swiss Cheese Model)。啥意思?就是多层防御。每一层防御(每一片奶酪)都可能有自己的“漏洞”,但把好几层叠在一起,漏洞对齐、让坏东西正好穿过去的概率就大大降低了。
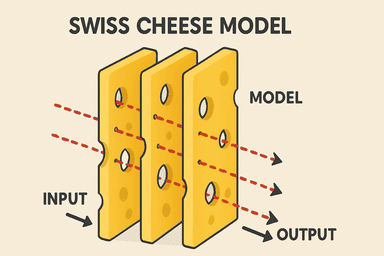
在 Anthropic 的这套体系里,主要有这么几层“奶酪”:
- 输入分类器 (Input Classifier): 这是第一道关卡。用户输入的问题或对话,先被它过一遍。如果发现有明显的恶意企图或包含“违禁”内容,直接拦截!
- Claude 模型本身: 就算输入侥幸过关,Claude 模型在生成回答前,自己内部也有一套判断机制。如果觉得这个问题不太对劲,它可能会主动拒绝回答(“对不起,这个问题我不能回答”)。
- 输出分类器 (Output Classifier): 这是最后一道防线,也是个狠角色。它会实时盯着 Claude 生成的回答。一旦发现输出内容“不对味”,比如偷偷包含了有害信息或者绕着弯子想使坏,它会立刻“叫停”,阻止这个回答发送给用户。
这三层各司其职,特别是输入和输出分类器关注点不同,大大增加了“越狱”的难度。用户很难直接“贿赂”那个只看最终输出结果的“巡逻警察”。
训练“安检员”的秘诀:合成数据与惊人的灵活性
那这些“安检员”(分类器)是怎么训练出来的呢?总不能让人天天编造各种有害问题吧?Anthropic 用了一个很聪明的方法:生成合成数据 (Synthetic Data)。
他们让 Claude 根据“宪法”里定义的有害/无害类别,自动“脑补”出成千上万种具体的、可能的用户请求和对应的(不该出现的)有害回答。比如,“宪法”里说不能教人获取危险材料,Claude 就能自动生成“去哪里买XX材料?”“XX材料在某地合法吗?”等具体问题。
用这种方法生成海量训练数据,效率高,覆盖面也广。
最妙的是它的灵活性。 以前发现新漏洞或新的有害话题,可能得重新找人标注海量数据,搞不好还得熬几个大夜。**现在?改改“宪法”里的几句话,比如加一条“讨论最新的网络钓鱼手段细节是不行的”,然后用新规则重新生成数据、训练下分类器,一杯咖啡没喝完,新‘补丁’就打上了,感觉有点不真实(但很爽)!
更棒的是,这些分类器是独立于 Claude 主模型的。更新分类器,基本不影响 Claude 本身的语言能力和风格,用户体验更稳定,部署也更快。
实战效果如何?从“几分钟”到“几千小时”的越狱难度
说了这么多,这套“宪法分类器”体系到底管不管用?Anthropic 可是下了血本,请了专业的红队(专门模拟黑客攻击的安全测试团队)来“硬刚”。
结果相当惊人:
- 之前: 对于没有这套系统的模型,在网上随便找个公开的越狱方法,可能几分钟就能让模型“就范”。
- 之后: 用上宪法分类器后,根据 Anthropic 公开的信息和演示挑战,顶尖的红队成员需要花费数千小时的尝试,才有可能找到一个通用越狱方法。
从几分钟就能‘策反’AI,到现在需要红队大佬们爆肝几千小时才可能找到一个通用‘后门’... 这难度系数,可以说是指数级上升了,够那些想动歪脑筋的人喝一壶的。
当然,凡事有利有弊。最初版本的分类器也带来一个问题:误报(False Positives)。就是过于“紧张”,把一些正常的、无害的问题也给拦截了。一开始确实有点‘宁可错杀一千,不放过一个’的意思,据说早期版本能把超过 40% 的良性请求给毙掉,简直快成一块“石头”了。

好在,通过不断优化“宪法”规则(特别是明确哪些是“无害”的)、改进训练数据,这个问题得到了极大改善。根据 Anthropic 的分享,新系统的误报率已经降到了 3% 左右。虽然还有进步空间,但这已经是巨大的飞跃,在提升 AI 模型鲁棒性的同时,尽可能保证了模型的实用性。
未来之路:持续进化,构建更负责任的 AI
“宪法分类器”是 AI 安全领域一个很酷的进展,但这绝不是终点。Anthropic 也在探索更多配套措施,比如:
- 快速响应机制: 一旦发现新的越狱方法,能迅速更新“宪法”和分类器,打上“补丁”。
- 持续监控与事件检测: 对模型使用情况进行监测,及时发现异常或漏网之鱼。
- 漏洞奖励计划: 鼓励外部安全研究人员报告漏洞。
https://www.anthropic.com/rsp-updates
最终的目标,是在享受 AI 强大能力的同时,将其风险控制在可接受范围内。这需要持续的投入、透明的沟通,以及像“宪法分类器”这样既聪明又实用的技术创新。
写在最后
总的来说,Anthropic 的宪法分类器提供了一种相当务实且灵活的思路,来应对 AI 越狱这个棘手的问题。它就像是给日益强大的 AI 模型量身定做了一套既懂规则、又能快速学习进化的“智能防护服”。虽然完美的安全可能永远无法达到(就像没有绝对撬不开的锁),但这种多层次、能适应变化的防御体系,无疑大大提高了门槛,让我们在探索 AI 未来的路上,能多一份安心。
你对这种 AI 安全策略怎么看?或者在使用 AI 时遇到过哪些让你觉得“不安全”或“哭笑不得”的瞬间?欢迎关注凌顺实验室公众号留言说出你的看法。
